This is a demo page accompanying the paper “Decode, move and speak! Self-supervised learning of speech units, gestures and sounds relationships using vocal imitation.”

| Original sound | Articulatory synthesizer |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Original sound | No inductive bias |
|---|---|
|
|
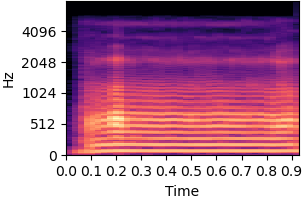
|
|
|
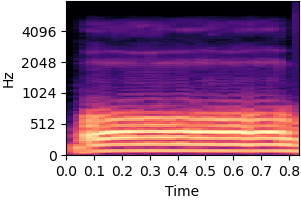
|
|
|
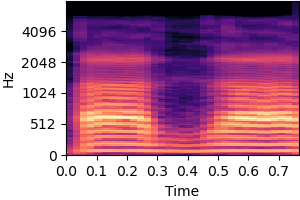
|
|
|
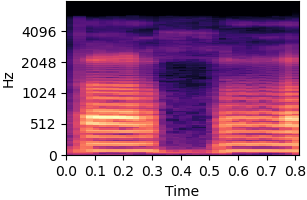
|
|
|
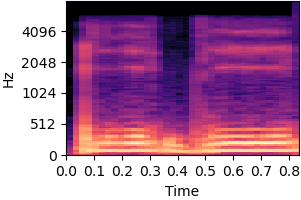
|
|
|
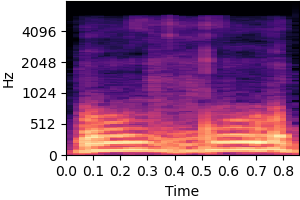
|
| Original sound | Static bias |
|---|---|
|
|
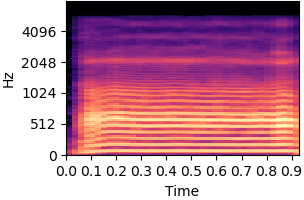
|
|
|
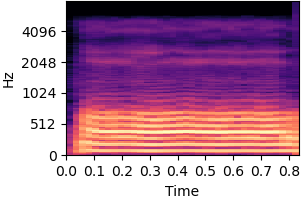
|
|
|
|
|
|
|
|
|
|
|
|
|
| Original sound | Dynamic bias |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Original sound | Static and dynamic bias |
|---|---|
|
|
|
|
|
|
|
|
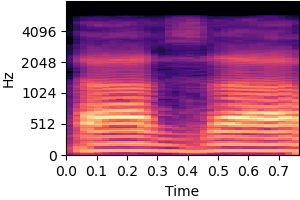
|
|
|
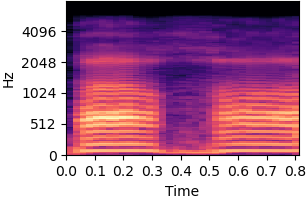
|
|
|
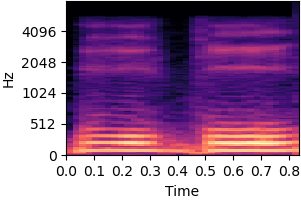
|
|
|
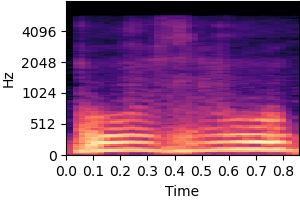
|